A Brief Introduction to Convolutional Neural Network
Convolutional Neural Networks and Popular CNN Architectures
A Convolutional Neural Network (CNN) is an artificial neural network model designed with inspiration from the visual cortex of the brain, primarily used for computer vision applications such as image classification and object detection. A standard CNN comprises three key layers: convolutional layers, pooling layers, and fully connected layers. These layers are arranged to form the feature extraction and image classification components of the neural network. The most important operation in a CNN is the convolution operation because of its ability to extract important features. The main drawback of CNNs is that it requires a lot of training data and computational resources.
The CNN architecture
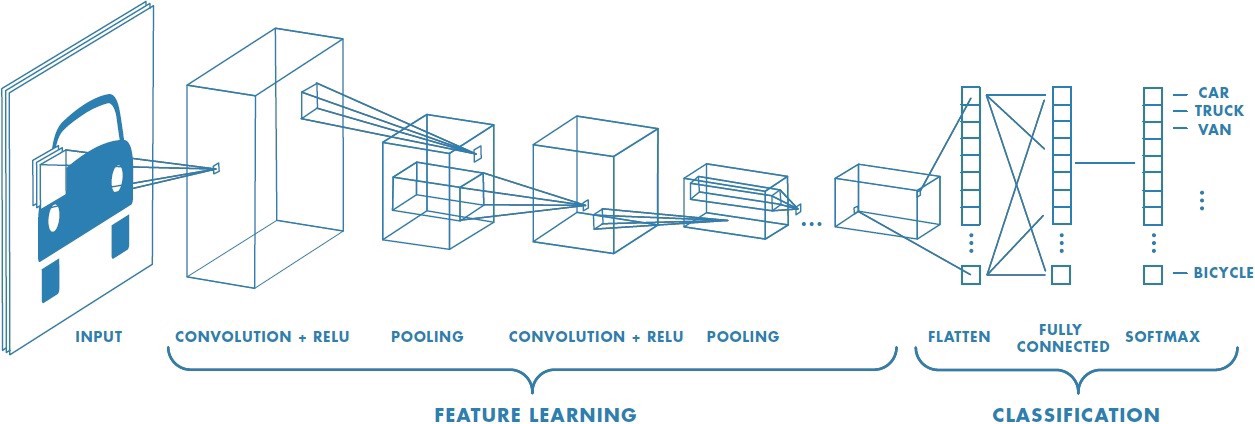
Layers in a Convolutional Neural Network
Convolution Layer
Convolutional layers employ learnable filters (also known as kernels) to carefully scan images and extract key features. These filters function as detectors, identifying and highlighting patterns such as edges, corners, and squares, allowing for accurate image understanding and analysis.
Convolution Operation
Convolution is a mathematical operation that combines two sets of information. In the context of neural networks, a kernel is employed to traverse the input matrix, resulting in the creation of a feature map. The process involves matrix multiplication and the summation of the outcomes.
In the illustrated example, the pixels highlighted in pink undergo multiplication with a 3x3 filter, and the results are aggregated to yield a value of 3 in the feature map. The use of a stride, set to 1 in this case, determines the size of the steps taken by the convolutional filter. With a stride of 1, the filter moves pixel by pixel across the input.
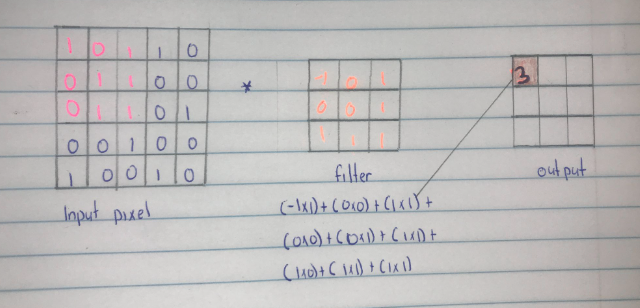
Pooling layer
Pooling layers act as data compressors, shrinking the size of feature maps extracted by convolutional layers. This dimensionality reduction not only enhances computational efficiency but also mitigates overfitting, allowing the network to generalize better to unseen data. Despite this "downsampling," pooling cleverly retains the essence of the features, ensuring the network focuses on what truly matters for the learning task.
Pooling operation
Pooling can be then in three ways, average pooling, max pooling and min pooling. The most commonly used methods are max pooling where the maximum value in a given patch is considered and min pooling where the minimum value in a given patch is considered. The pooling filter should be less than the feature map. In the diagram below we use 2X2 filter, a stride of two and max pooling to reduce the feature map by a factor of 2.
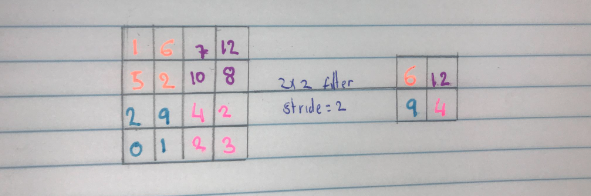
Fully connected(dense) Layer
After the feature extraction, flattening is performed to convert the pooled feature maps to a linear vector which is fed into the fully connected layer.
The fully connected layer outputs confidence scores which are used to determine which class the image belongs to.
CNNs have many layers and filters. The first layer usually extracts the basic features like edges, this is then passed to next layers which detect more complex features. This feature detection continues as the network gets deeper and in the end it is able to detect the complex features.
## Sample CNN architectures
Availability of labeled data and computational resources has led to popularity of CNNs leading to many architecture innovations and improvements in the performance of the CNN.
### AlexNet
It has eight layers and 3 layers are fully connected layers. AlexNet has ReLu activation functions, a max-pooling layer and a dropout layer to prevent overfitting.
### GoogleNet
Has 22 layers
GoogleNet is made of subnets called inception to help cover a larger area and also handle objects at different scales.
### VGG
VGG introduces several 3x3 kernel-sized filters that are next to each other. The number represents the number of weight layers on each variant e.g vgg16 has 16 layers.
The VGG-16 consists of 13 convolutional layers and three fully connected layers
### ResNet
ResNet introduced skip connections which help to introduce rich feature maps from lower levels.
## Tasks where CNNs excel
CNNs perform best in computer vision tasks like:
- Image processing
- Video analysis
- Facial recognition
- Because of their ability to do feature extraction, The different architectures are modified to carry out different tasks. for example, with segmentation tasks the fully connected layers are replaced with upsampling layers.